

Beyond "Pick Two": Real-World Trade Offs
Why most systems live between CP and AP and how to choose where yours belongs.

This is Part 4 of a 4-part series on the CAP Theorem and distributed systems trade-offs. Read Part 1, Part 2, or Part 3 if you haven’t already.
We’ve dedicated three posts to treating CP and AP as binary choices. etcd is CP. DynamoDB is AP. Pick a side.
But that’s not how real systems work.
MongoDB can be CP or AP depending on your configuration. Cassandra lets you choose per query. Even PostgreSQL, which we covered as a CP system in Part 2, flips to AP behavior with async replication. The line between strong consistency and high availability isn’t a binary switch…..it’s a spectrum.
And then there are the systems that seem to ignore CAP entirely. Google Spanner claims to be both consistent and available. CockroachDB markets itself as “ACID at scale.” What’s going on?
The answer comes down to understanding what CAP actually constrains, what happens when networks don’t partition, and how some very smart engineers found ways to work around the edges.
PACELC: The Other Half of the Story
CAP Theorem is very prescriptive. It only tells you what happens during a network partition. But what about all of the other times? The times the network is working just fine? The other 99% of the the time?
That’s where PACELC (pronounced “pass-elk” but I refuse to pronounce it in any other way than “pace-l-c”). Introduced by Daniel Abadi in 2010, it extends the CAP Theorem by actually including what to choose when the network is fine.
PACELC stands for Partition, Availability, Consistency, Else, Latency, and Consistency.
The way it’s read is “If there’s a network (P)artition, choose between (A)vailability and (C)onsistency. (E)lse, choose between (L)atency and (C)onsistency.
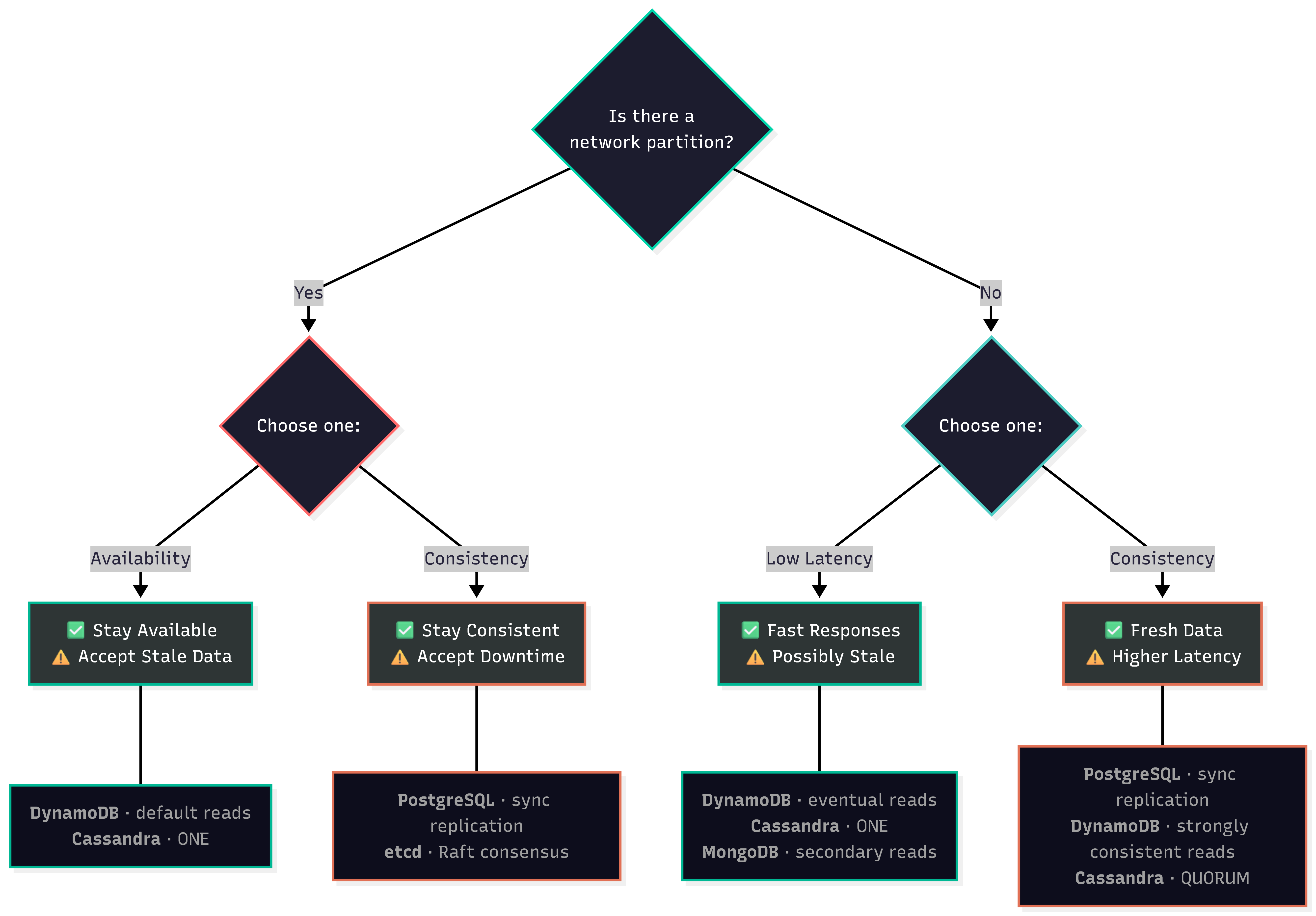
That “Else” is doing a lot of heavy lifting. Even when your network is perfectly healthy, distributed systems still face a fundamental trade-off: do you want fast responses or strong consistency?
The Latency vs Consistency Trade-off
Let’s think about it for a second. To guarantee strong consistency, we showed that a system needs to coordinate between multiple nodes. We established that coordination takes time (a cross-region round-trip is about 50-200 ms). That’s the price of every coordinated read / write.
You want the most up-to-date value? You need to check with multiple replicas or go to the leader. Those are extra round trips. You want an instant response instead? You can read from the nearest replica, but also come to terms with the fact that it could be slightly behind.
This trade-off exists even in perfect networks. It takes time to send data and coordination isn’t free.
PACELC in Practice
Let’s map the systems we’ve covered to both sides of PACELC:
DynamoDB:
P+A: During a network partition, choose availability via eventually consistent reads. Eventually consistent reads stay available during partitions, any replica can serve them.
E+L: During a clean working network, choose latency. Those default eventually consistent reads optimize for latency by hitting the nearest replica. Flip to strongly consistent reads and you’re trading latency for consistency, even when the network is healthy.
Cassandra:
P+A: During a network partition, all node remain available for reads and writes. Remember, Cassandra is leaderless, so there’s no leader to lose.
E+L or E+C: During a normal working network, you get to choose what you want: latency or consistency. Remember that Cassandra allows you to choose per query.
ONEoptimizes for latency (E+L).QUORUMoptimizes for consistency (E+C). Same cluster, same data, different trade-offs.
MongoDB:
P+A/C: A little different than the others, MongoDB changes between availability and consistency depending on the operation. During partitions, the minority side remains available to serve reads from the secondaries (P+A). But, writes still require the leader, which lives on the majority side (P+C). So reads fall towards P+A and writes fall to P+C.
E+L/C: During normal operations, MongoDB defaults to reading from the primary. Which means you’re getting strongly consistent reads. You can set
readPreferencetonearestwhich would give you the fastest response. There’s alsoreadConcernwhich defaults tolocalwhich says get the most recent data, regardless of whether it’s been replicated.
Traditional RDBMS (PostgreSQL with sync replication):
P+C: During network partitions, if the primary can’t reach it’s synchronous replica, writes block. They don’t immediately fail and they don’t get dropped….it just hangs. The system would rather stall than be inconsistent.
E+C: During normal operation, every write still waits for every replica to acknowledge before confirming the write. That’s added latency for every single write irrespective of partitions. Postgres pays the consistency tax every single time, not just during partitions.
Notice a pattern? PACELC shows why “eventually consistent” systems like DynamoDB feel fast and reliable in normal operation, they’re optimizing for the common case (no partition, low latency) while accepting trade-offs during the rare case (partition, stale reads). Meanwhile, CP systems pay the latency tax all the time, partition or not.
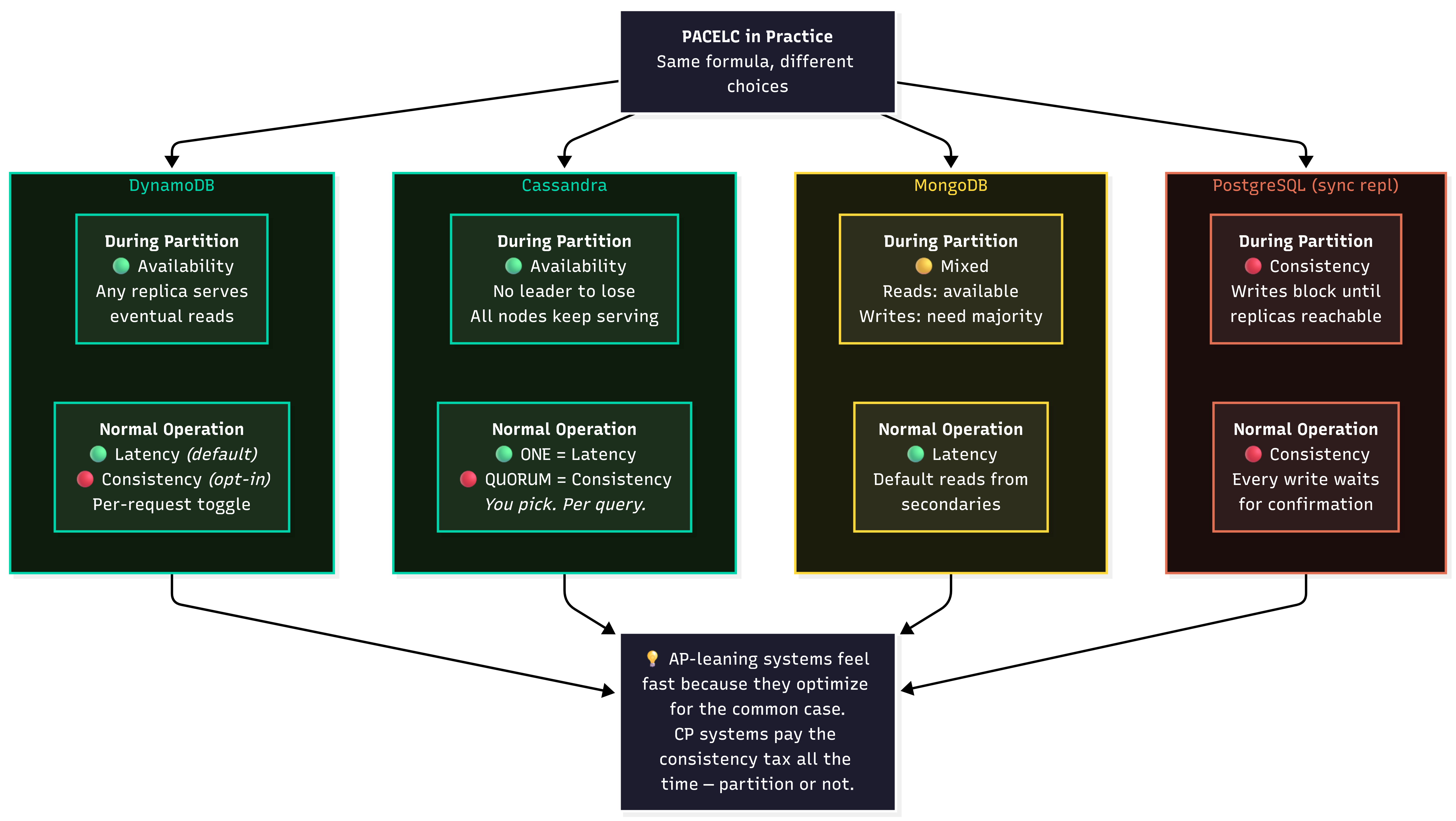
This is why your strongly consistent database feels slower even when nothing is broken. It’s not a bug. It’s the ELC trade-off in action.
The Consistency Spectrum
CP vs AP suggests two positions on the consistency scale: strong or eventual. Reality shows us that there is way more to this spectrum.
We covered some of these in Part 3: read-your-writes, monotonic reads, causal consistency. But here’s the full picture as a spectrum, from strongest to weakest:
Linearizability: The gold standard. Every operation appears to take effect instantly at a single point in time. Every read returns the most recent write. We established before that this is what CAP calls “consistency.” It is also the most expensive form of consistency. It requires coordination on every operation.
Sequential Consistency: A little more lax. All operations still appear in some total order but, may or may not line up according to wall clock. For example, if User A writes at 12:00:01 and User B writes at 12:00:02, the system might order User A first or second. Really doesn’t matter, what matters is that everyone sees the same order. Imagine it as a globally agreed-upon order.
Causal Consistency: Even more lax than above. Only cares about cause and effect. If two operations are independent of each other it doesn’t matter what order it’s shown in. However, if two operations are dependent on each other (B on A), everyone must see A before B.
Read Your Writes: Scoped to a single client. If Client A writes something, subsequent reads are guaranteed to reflect that write. Other clients may or may not see it yet. This is the bare minimum for user experience: “I just posted a comment, why can’t I see it.”
Monotonic Reads: As the name suggests, time only moves in one direction, forward. Once you’ve seen a value, you are guaranteed to not see an older version of that value. If this wasn’t guaranteed you could refresh your page and see different data.
Eventual Consistency: The weakest model on this list. Basically, all replicas will eventually converge to the same value. Eventually. Nobody knows how long that eventually is. It’s not bounded by anything.
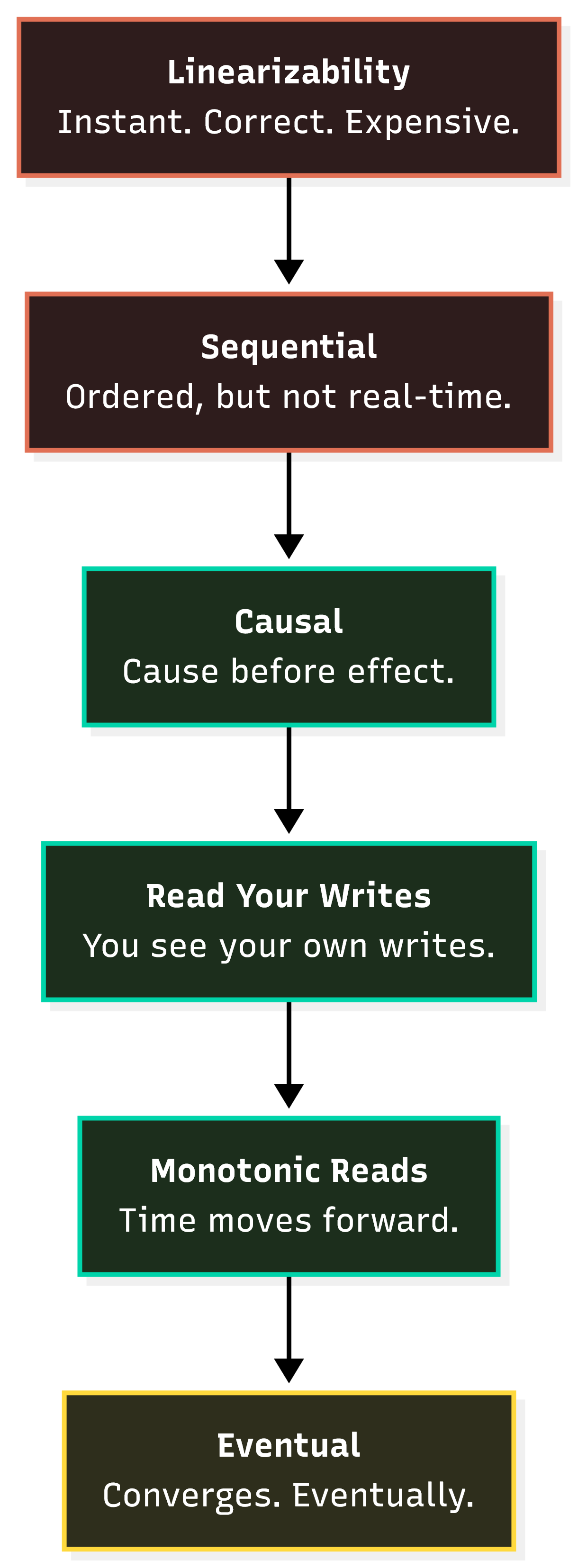
This is a useful mental model to have, not a perfect taxonomy. Some of these consistency models apply at the global level and others at the session level. But the information is useful to illustrate that there is plenty of room between linearizability and eventual consistency.
Why the Middle Matters
Most applications don’t need pure linearizability everywhere and many can’t tolerate bare eventual consistency everywhere either. So what do we do? The answer is…a mix of both.
Let’s do a thought experiment. Let’s assume we have a social media feed. We don’t really care about having likes and comments ordered perfectly, right? But there are areas where we need guarantees stronger than eventual consistency:
When you publish a post, you should be able to see it immediately (read-your-writes).
Once you’ve seen a comment, it shouldn’t just disappear just because the backing store is stale (monotonic reads).
A reply should appear after a post it’s responding to has published (causal consistency).
Those guarantees are definitely weaker than linearizability, but map much better to the expected user experience real applications need. Best part? All three can exist with high availability.
This is the insight that drives modern database design. Instead of forcing you into “consistent” or “available,” systems give you a dial. Cassandra’s tunable consistency. DynamoDB’s per-request read mode. MongoDB’s read concern and write concern settings. They’re all implementations of this spectrum.
The question isn’t “CP or AP?” It’s “how much consistency do I actually need for this specific operation?”
Systems That Claim to Beat CAP
Some distributed systems seem to ignore CAP entirely. Strong consistency and high availability. Globally distributed and fast. What’s the catch?
There’s always a catch.
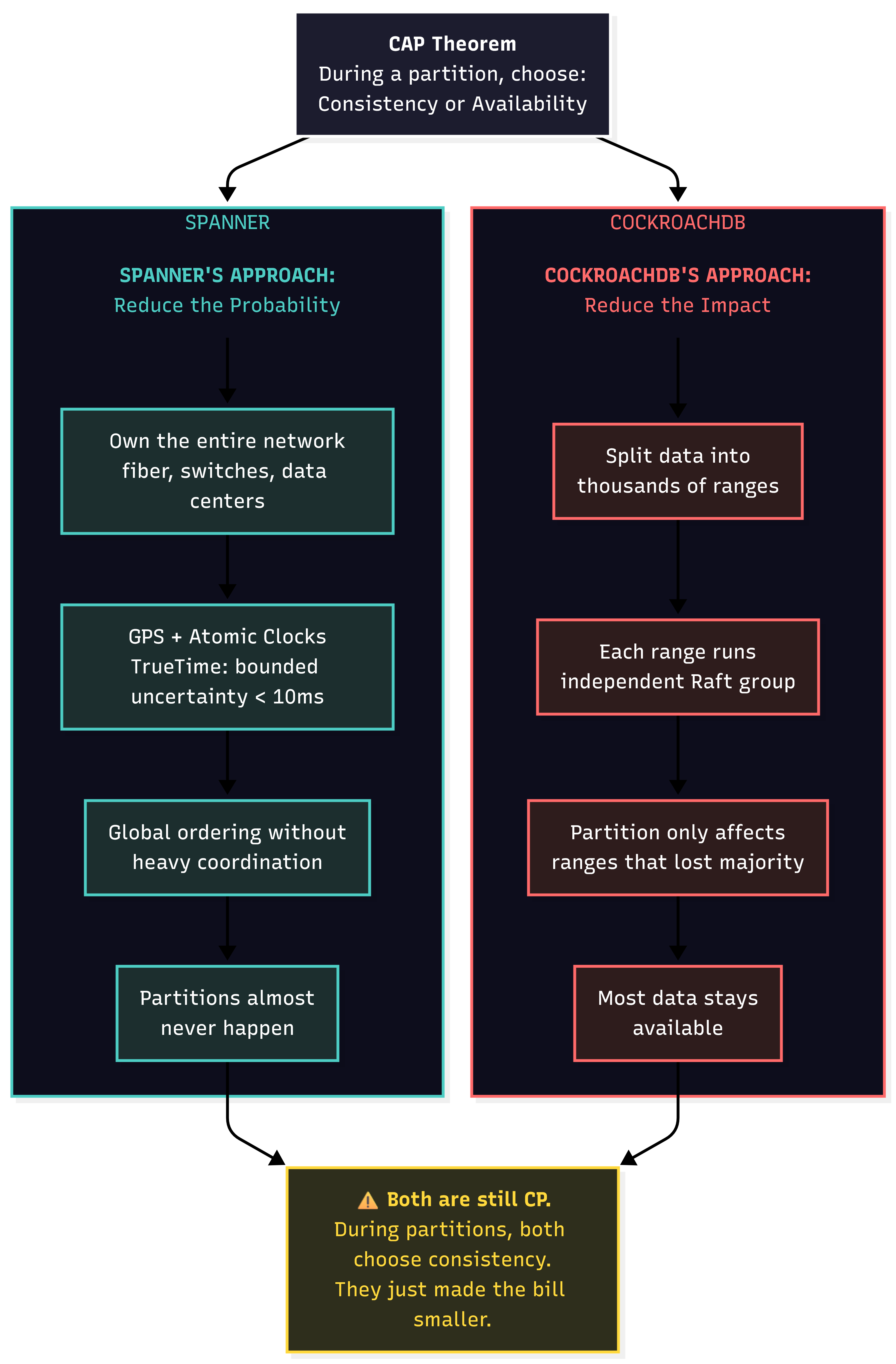
Google Spanner: Throw Hardware at the Problem
Google Spanner, a globally distributed SQL database, advertised as “always-on” is always brought up when discussing the CAP theorem. Spanner is able to provide globally distributed, strongly consistent ACID transactions. Sounds too good to be true, no?
Well it is. Spanner relies on a global timestamp (their secret weapon here) to order events. TrueTime, is a global timestamp with bounded uncertainty, powered by GPS receivers and atomic clocks. Yes, you read that right, actual GPS receivers atomic clocks are physically bolted to Google server racks. By knowing that an event happened between time T and T+ε (where ε is typically less than 10ms), Spanner can order events globally without the extensive coordination that other CP systems require.
That solves our latency issue during regular operations. But what about when there’s a network partition?
During a network partition, it chooses consistency over availability. Spanner is still CP. Full stop. The reason it appears to also be highly available is that Google’s network almost never partitions, because Google owns the fiber, the switches, the data centers, and the custom hardware. Spanner’s availability story isn’t an architectural breakthrough. It’s an infrastructure advantage that many companies simply can’t replicate.
Eric Brewer (the guy that coined the CAP Theorem) admits that Spanner is technically CP, it just happens to operate in an environment where the P is heavily minimized.
If you’re not Google, you don’t have TrueTime. And if your network actually partitions, Spanner makes the same choice as etcd: consistency wins, availability loses.
CockroachDB: Make the Pain Invisible
CockroachDB takes a completely different approach. Instead of trying eliminate or minimize partitions like Google, it aims to hide the partitions from the user.
Under the hood, CockroachDB uses Raft consensus, the same protocol we covered in Part 2 with etcd, for replication. But where etcd uses a single Raft group for the whole cluster, CockroachDB splits the data into ranges, each running its own independent Raft group. Each range replicates across multiple nodes and has its own node leader.
So how does it stay “available” if it’s running consensus?
The trick here is scope. During a network partition, CockroachDB does not go down in its entirety, only the specific ranges that lost their majority. Let’s say that again. During a network partition, only ranges that lose the majority go down. For example, if a partition cuts off one node in a five-node cluster, only the ranges where that node held the deciding vote are affected. Everything else keeps working as if nothing happened.
It’s technically CP behavior. But by distributing ranges across many nodes and rebalancing automatically, the practical impact of any single partition is small. Most users won’t notice.
CockroachDB didn’t hack the CAP Theorem, it just made the decision extremely granular. You’re still compromising availability during partitions, it’s just for a small-subset of the data.
The Pattern
As we’ve shown, neither of these systems actually violate the CAP Theorem. They just engineered around it from opposite directions. Google’s Spanner reduces the probability of partitions by owning the entirety of the infrastructure. CockroachDB reduces the impact of partitions by splitting the data into numerous independent ranges.
The constraints are still there. Networks are still bound to fail and when that inevitably happens, both systems default to choosing consistency over availability. The difference, however, is that both systems have found ways to make the consistency vs. availability choice less painful. Spanner by making partitions almost nonexistent. CockroachDB by making them almost invisible.
The lesson? CAP describes fundamental constraints. Creative engineering minimizes their impact. But the constraints are still there, waiting for the network to have a bad day.
How to Actually Choose
Alrighty, we’re on our fourth post. Four posts of theory, papers, and systems deep-dives. Let’s get a bit practical. How do you actually decide between consistency and availability for your system?
Start with Three Questions
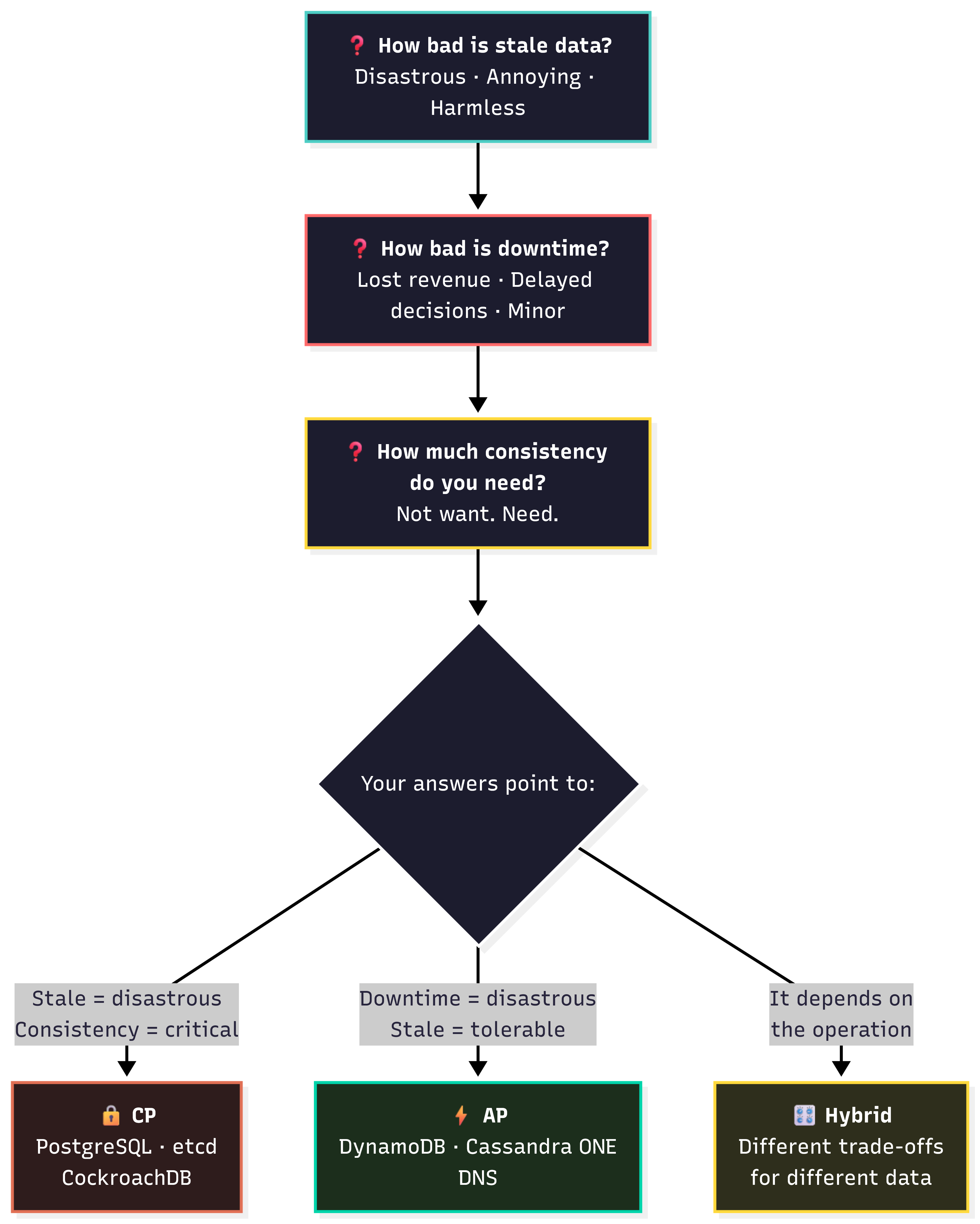
Step 0, before even picking technologies, assess the system you’re building. Answer these questions honestly.
1. What happens if users see stale data?
Obviously stale data is not ideal. But this question is more geared towards the user-experience if stale data is presented. For a bank, a stale bank balance has real financial implications for the user. However, for a social media app, a like counter doesn’t really have that big of an affect. An example to think about, DNS has tolerated stale records for decades. Decades. That’s not to say to pick a certain path, but to drive home the point “not everything needs to be strongly consistent”.
2. What happens if the system is unavailable?
We would all love 100% system uptime. AWS spends billions of dollars to achieve four 9’s of availability (still not 100%). Where stale data affects user-experience, system availability is usually tied to business performance.
A payment processor being down is lost revenue. An analytics dashboard being down leads to delayed decisions. A configuration service being can lead to failures across all components that config controls (which might be worse than stale data). The answer isn’t always obvious, but you need to think through what happens when your system is down.
3. How much consistency do you actually need?
Let’s re-read that question, how much consistency do you actually need? Notice need not want.
Bank balances are strictly linearizable, there’s no way around it. Shopping carts can get away with something weaker (causal consistency). Social features just need read-your-writes level of consistency and they’re good. You need to be very honest here. Every step up the consistency ladder is a step down the latency or throughput ladder.
The Approach That Actually Works: Hybrid
What I’ve learned from working on, operating, and researching distributed systems is that almost nobody should go pure CP or pure AP. The right answer is almost always somewhere in the middle. Different data has different requirements and it should be treated that way.
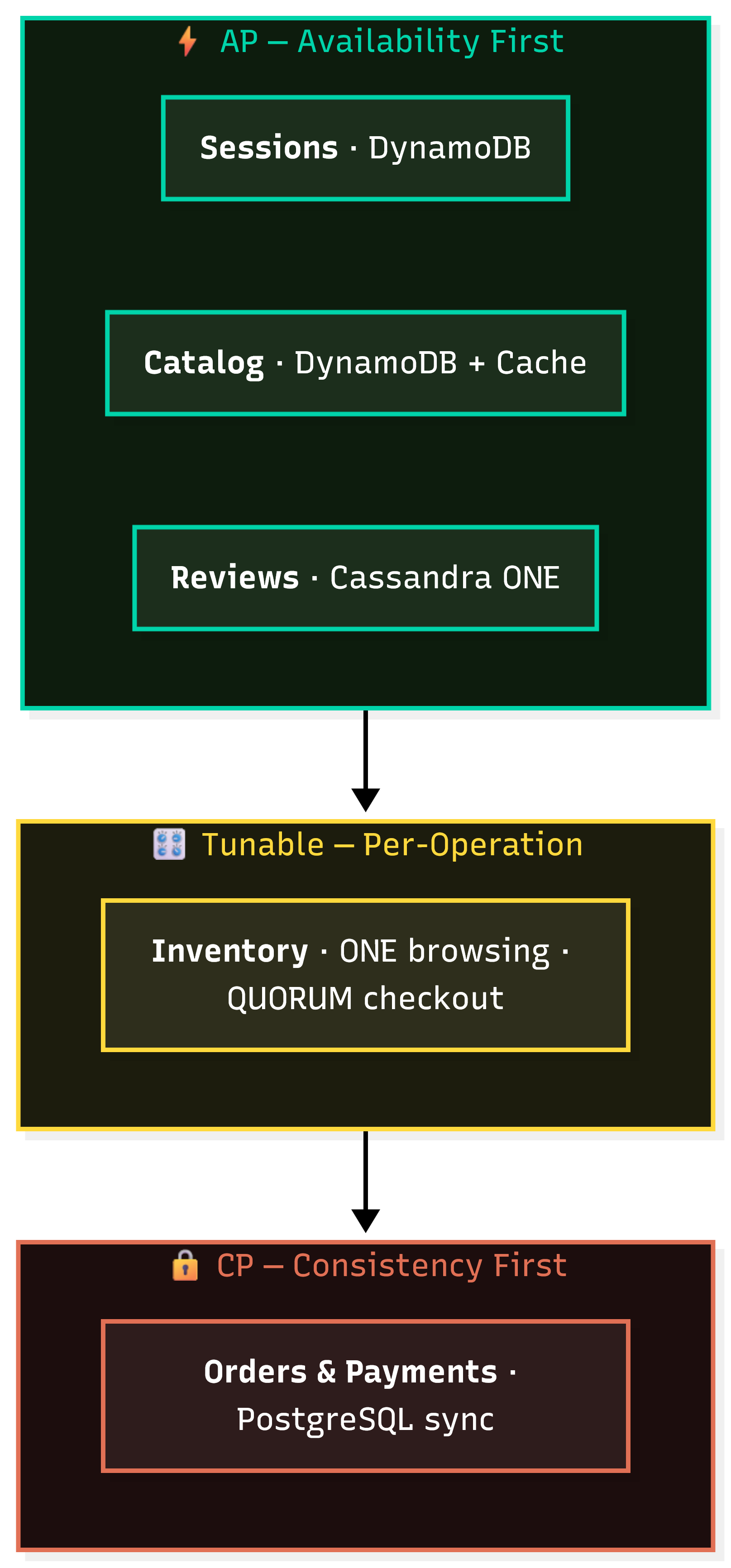
Here’s what that looks like for an e-commerce system:
User sessions → AP. Throw this in DynamoDB with eventually consistent reads. Fast logins, and who cares if a session is slightly stale? If it breaks, the user logs in again.
Product catalog → AP. Fast browsing matters more than showing the absolute latest product description. Cache aggressively. Invalidate when you can.
Inventory → Tunable. This is the interesting one. You can be optimistic (AP) when browsing — show approximate stock levels. But when the user actually clicks “Buy,” switch to a strongly consistent check before charging their card. Cassandra with ONE for reads and QUORUM for the purchase path, or DynamoDB with eventually consistent reads for browsing and strongly consistent reads at checkout.
Orders and payments → CP. No debate. Money is involved. PostgreSQL with synchronous replication, or a distributed SQL database like CockroachDB. If the system can’t confirm consistency, it should refuse the write.
Reviews and social features → AP. Eventual consistency is totally fine here. A review showing up 2 seconds late doesn’t hurt anyone.
The pattern: use the weakest consistency model that still meets your requirements for each piece of data. Stronger consistency isn’t free, it costs latency, throughput, and operational complexity. Don’t pay for it where you don’t need it.
What CAP Actually Taught Us
Four posts. Thousands of words. Multiple papers. Here’s what it all boils down to:
CAP Is a Design Tool, Not a Law
CAP theorem doesn’t tell you what to build. It tells you what questions to ask. What should your system do when the network partitions? When nodes fail? When clocks skew? If you haven’t explicitly decided, your system will decide for you. If you’re lucky that looks like 3AM debugging sessions on the weekend.
Nothing is Free
CAP’s lasting contribution is killing the fantasy that distributed systems can provide everything for free. Every guarantee has a cost:
Strong consistency costs latency and availability.
High availability costs consistency guarantees.
Partition tolerance isn’t optional, networks fail.
Understanding these costs turns you from someone who hopes their system handles edge cases into someone who knows what their system will do when things go wrong.
The Spectrum Is Your Friend
The real world isn’t CP or AP. It’s a spectrum, and modern systems give you a dial. Cassandra’s tunable consistency, DynamoDB’s read modes, MongoDB’s read/write concerns, all of these exist because the engineers who built them understood that different data deserves different trade-offs.
The best distributed system for your use case isn’t the most consistent one or the most available one. It’s the one that makes the right trade-offs for your specific requirements. And now you know how to figure out what those trade-offs are.
Series Recap
We started this series with a simple question: what does “you can only pick two” actually mean?
Part 1 busted the myth. CAP isn’t about permanently picking two properties. It’s about what your system does during a network partition — and that choice is binary: consistency or availability.
Part 2 explored the cost of being right. etcd, Zookeeper, PostgreSQL, and MongoDB showed us what strong consistency demands: quorum writes, leader elections, blocked operations during partitions, and latency on every write even when the network is healthy.
Part 3 explored the cost of staying up. DynamoDB, Cassandra, and DNS showed us what high availability demands: stale reads, conflict resolution strategies, and the operational complexity of reconciling data after the network heals.
Part 4, this part, showed that the binary choice was never the full story. PACELC revealed that you’re making trade-offs even when the network is fine. The consistency spectrum gave you six stops between linearizability and eventual consistency. And the hybrid approach showed that real systems don’t pick one side — they pick different trade-offs for different data.
Next time someone draws a triangle on a whiteboard and asks you to “pick two,” you’ll know exactly why that’s the wrong question — and what to ask instead.
— Ali
References
Consistency Tradeoffs in Modern Distributed Database System Design — Daniel Abadi (2012), the PACELC paper.
Spanner: Google’s Globally Distributed Database — Corbett et al. (2012)
Spanner, TrueTime and the CAP Theorem — Eric Brewer (2017), where Brewer himself explains why Spanner is technically CP.
Designing Data-Intensive Applications — Martin Kleppmann
Jepsen Analysis — Real-world consistency testing of distributed systems.
Series Index
Beyond “Pick Two”: Real-World Trade-offs ← You are here