

Merkle Trees 101
Today we're going to take a in-depth look at Merkle Trees, a fundamental data structure in the field of cryptography and an exhaustively used one in the context of blockchain and distributed systems.

Hey folks, I’m back for another post. I’m doing decently well in keeping up with my promise of weekly posts. I do, however, apologize for the posts not coming out on set dates and time as I originally promised.
Before we delve into the weekly topic, I’d like to welcome the 36 (at the time of writing this) new subscribers. I’d just like to say thank you so much for supporting my work here. We went from 12 subscribers from my last post, all the way to 48 at the time of writing this. The growth is beyond what I initially imagined. Thank you to all my subscribers, if you’re new here I hope you’ll enjoy my posts.
Some of the feedback I’ve received from readers:
Also I'm not sure if I said this before but it's a great thing you're doing and I've read all of your articles thus far. I hope you keep doing it and I wish you success!
Thanks for sharing this post, Ali. I have been learning this more deeply during my studies, but I never saw a simple summary and overview like this one. It was a nice journey!
This may seem like a random topic, but I’m currently taking a cryptography class and my project idea is related to homomorphic encryption. While doing some preliminary research into the topic I stumbled across Merkle trees and distributed filesystems. So, naturally, I decided to make it the topic of my post in hopes of learning more about them and imparting some knowledge.
So, without further adieu…enjoy.
Before we can dive into Merkle Trees we first have to talk about plain old trees.
What is a Tree?
A tree is a data structure in computer science that represents a hierarchical tree structure composed of nodes. Each node can be connected to many children, but can only have one parent node, this is not the case for the root node. The root node has no parents, it’s the top-most node in the tree. Nodes with no children are called leaf nodes. Below is a figure that explains this in a visual manner:

Using the visual above lets classify the different types of nodes:
Root Node: the root node in the above tree is Parent. The parent node has no…parent.
Children Nodes: James, Thomas, Nick, and all of the Grandchildren are children nodes.
Leaf: the leaf nodes of a tree are the children nodes with no children of their own. So in this case, all of the Grandchildren nodes are leaf nodes as they do not have any children of their own.
The constraints put on the nodes is actually quite useful. This means that there are no loops in relations, meaning a node cannot be it’s own ancestor. Secondly, this means that we can consider each child node the root node of its own subtree. That might sound confusing but let’s use some visuals:
Let’s show the entire tree with leaf nodes and subtrees marked:
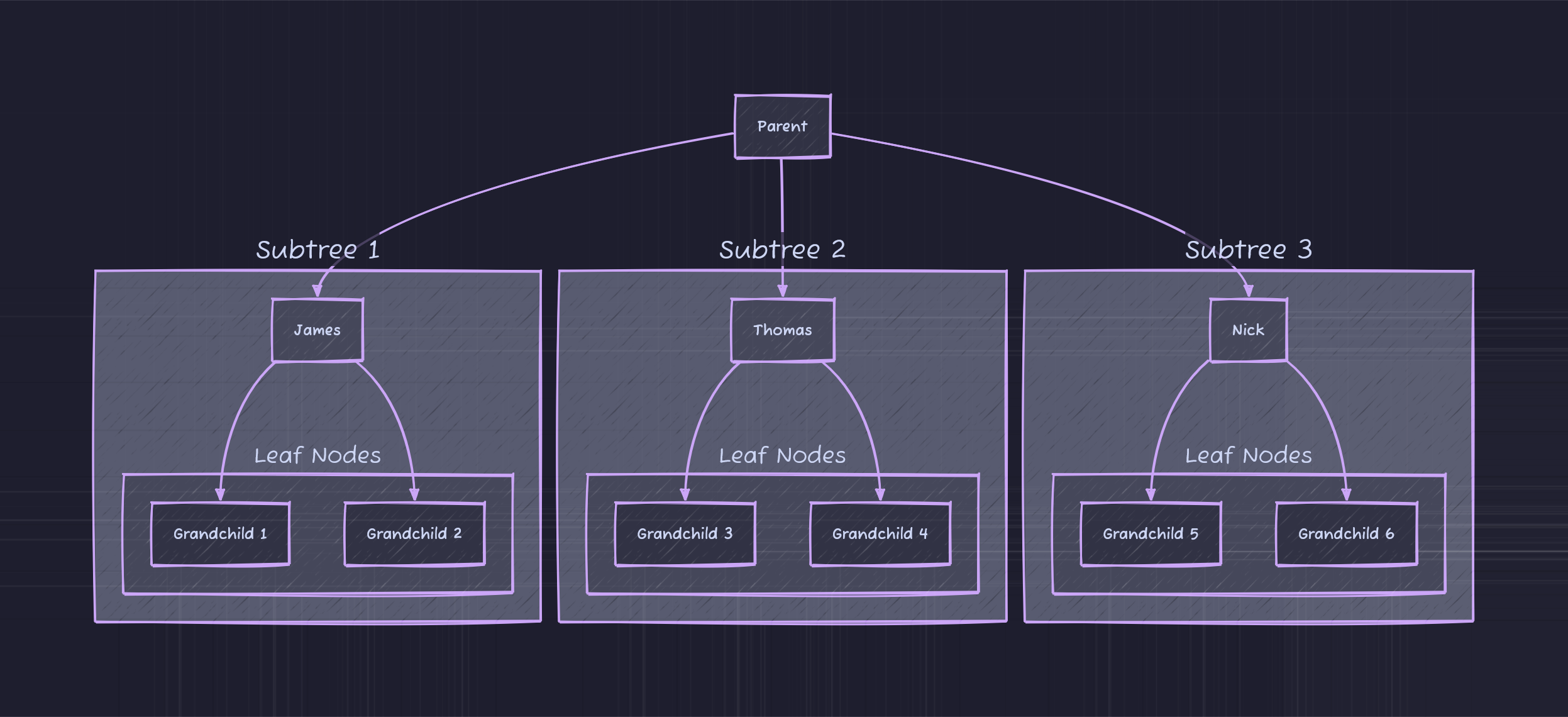
As shown, James, the child node of Parent, is it’s own root node within Subtree 1. This is true for all non-leaf children nodes of a tree.
With that in mind, how can we visit / access each node? This is called “walking the tree” or tree traversal.
Tree Traversal
We won’t be looking at tree traversal in-depth for this post, however, just at a high-level I’ll briefly describe the two most popular types.
Unlike linear data structures, which are traversed in a linear fashion (looping over the data structure itself and computing at each element), trees can be traversed in multiple ways. Two of the most common traversal types are breadth-first and depth-first.
Depth-First: go as deep into the tree as possible before moving to the next sibling.
Pre-Order: Visit root, then left subtree, then right subtree.
In-Order: Visit left subtree, root, then right subtree.
Post-Order: Visit left subtree, right subtree, then root.
Breadth-First: explore all nodes at the current depth before moving on, also known as level-order
We now have enough background info to tackle this weeks post…
What is a Merkle Tree?
A Merkle tree is a binary tree (just a tree where a node can have up to two children nodes), obviously, in which every leaf node contains the cryptographic hash of a block of data and every non-leaf node contains the cryptographic hash of the hashes of it's children (sounds confusing I’ll show a visual in a second).
Now, what this specific tree allows us to do is securely verify that arbitrary content exists within the tree.
Let’s get a visualization of a Merkle Tree:

As shown, the leaf nodes of the Merkle Tree are hashes of the underlying data block. Now, at the very top we have the root node, known as the Merkle Root. So why is this tree important? It allows us to verify data efficiently and securely without having to check each piece of data individually.
Inclusivity
So how can we verify that a piece of data is included in the merkle tree? By providing a Merkle Proof, aka an inclusion proof.
In an inclusion proof all we need is the leaf node’s (the data block being verified) sibling and all other intermediate hashes needed to calculate the merkle root hash. I’ll explain visually below:
Lets say we want to check if data block L1 is in the Merkle Tree. The way we would do that is:
Calculate
hash(L1)Use the Merkle Tree’s
Hash 0-1andHash 1This means that we will calculate
Hash 0using the Merkle tree’sHash 0-1and our computedHash 0-0
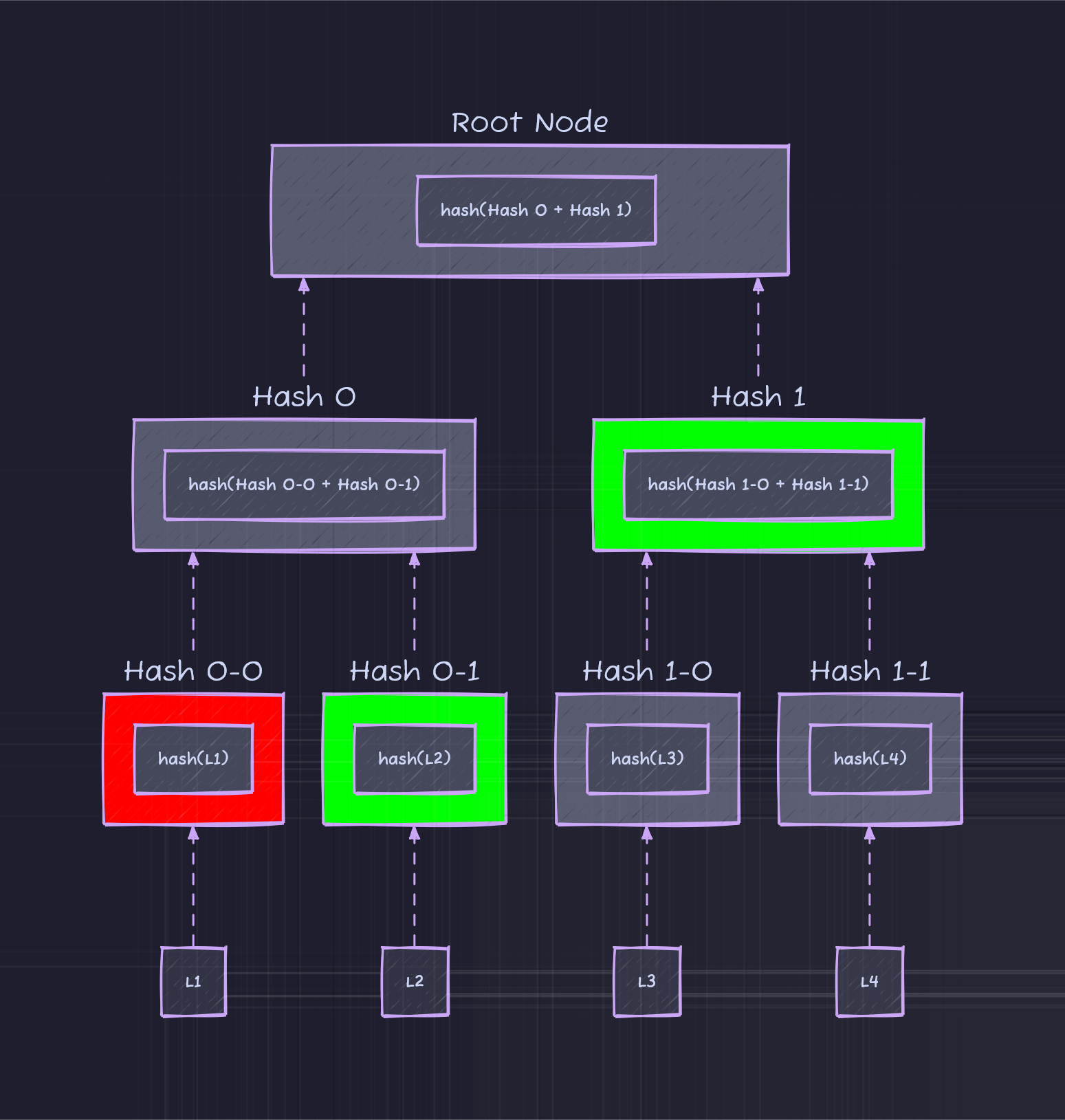
Once we have Hash 1 and Hash 0-1 we can calculate Merkle root and compare the two hashes to verify the exact content of L1.
This method of proofs is actually very advantageous when compared to linear data structures because it scales logarithmically. This means that we need to compute log(N) hashes to prove the inclusion of a data element, where N is the number of leaf nodes. As data grows this logarithmic scaling proves to be much more manageable.
So in our example above, we have four leaf nodes, so we only need log(4) hashes to verify any data block. Let’s see how that scales:
8 leaf nodes → log(8) → 3 hashes needed
16 leaf nodes → log(16) → 4 hashes needed
128 leaf nodes → log(128) → 7 hashes needed
1,000,000 leaf nodes → log(1000000) → 20 hashes needed
As the leaf nodes grow, the number of hashes to verify any individual data block grows at a sustainable pace.
Uses
So where do we see Merkle Trees today? Basically everywhere. The most common and prevalent usage of Merkle Trees is within the Blockchain and Cryptocurrency space. It’s a fundamental part of Blockchain technology, they’re used to verify and organize transactions efficiently within data blocks.
Blockchain Technology:
Bitcoin and Ethereum use Merkle Trees to efficiently verify transactions.
Simplified Payment Verification (SPV) allows lightweight clients to verify transactions without downloading the entire blockchain.
Distributed File Systems:
IPFS (InterPlanetary File System) uses Merkle Trees to address and distribute content, ensuring data integrity.
Version Control Systems:
Git uses Merkle Trees to manage file versions and ensure data integrity across repositories.
Peer-to-Peer Networks:
BitTorrent utilizes Merkle Trees to verify pieces of files downloaded from multiple peers.
Trusted Platform Modules (TPMs):
Use Merkle Trees to securely store cryptographic keys and verify system integrity.
So basically, Merkle Trees are everywhere from the file system on your computer to your version control system (Git, Mercurial) to distributed databases like Amazon DynamoDB and Google’s BigTable.
Conclusion
Merkle Trees play a crucial role in ensuring data integrity and efficient verification in distributed systems. Their hierarchical hashing mechanism allows for secure and scalable data verification, making them indispensable in modern technology.
For next weeks post we’ll be implementing Merkle Trees .
If you found this post helpful or have questions, please leave a comment below. Don't forget to subscribe to stay updated on future posts exploring fascinating topics in computer science and cryptography.
Thanks for tuning in,
Ali.
Very interesting post. This is my first time hearing about merkle trees and I'm glad I clicked on this post to learn more!