

Replication 101
Three ways to keep copies of your data, and the trade-offs of each.

Hey I’m back, for the next couple of weeks we’re going to focus heavily on the 101 series to build the foundational knowledge required to build complex systems. In the coming weeks we’ll take a look at Replication (this post), Sharding, Consistent Hashing, and more.
Enough of the intro, let’s get started.
If you’re running a database in production, chance are you’re running more than one copy of your data. A single node is a single point of failure. If it goes down, your data is gone (or at least, inaccessible until it recovers). Replication is the process of maintaining copies of the same data on multiple nodes.
But replication isn’t just about durability. It also enables read scaling (spread read traffic across multiple nodes) and geographic distribution (place copies of data closer to users in order to reduce latency). This was the core of the post about OpenAI’s scaling of Postgres.
This post walks through the three primary replication architectures: leader-follower, multi-leader, and leaderless. Each makes a fundamentally different trade-off between consistency, availability, and complexity.
Leader-Follower Replication
Leader-follower (also called primary-replica or master-slave) is the most common replication architecture. The model is straightforward:
One node is the leader (primary). All writes go to this node.
One or more nodes are followers (replicas). They receive a copy of every write from the leader and apply it to their own data.
Reads can be served by the leader or any follower.
Simply put, writes flow in one direction: leader to followers. Clients write to the leader and can read from anyone.

Synchronous vs. Asynchronous
The critical question within leader-follower replication is: when is a write considered confirmed?
Synchronous replication means the leader waits for at least one follower (sometimes all) to confirm that the write has been received and applied before acknowledging the write to the client. This guarantees that the follower has an up-to-date copy. If the leader dies, no committed data is lost.
The cost is latency. Every write is at least as slow as the round-trip time to the slowest required follower. If a follower is unreachable, writes can hang or fail entirely.
Asynchronous replication means the leader acknowledges the write immediately after writing to its own storage. Followers receive the update later. This is faster, but introduces a window where the leader has data that followers don’t yet. If the leader dies during this window, those writes are lost.

So which one do most systems use? In practice, asynchronous replication is the default. PostgreSQL, MySQL, and MongoDB all ship with async replication out of the box. You can configure synchronous replication in each, but the latency cost is significant (as we showed in the CAP Theorem Series Part 2 with PostgreSQL).
Replication Lag
Because followers receive updates after the leader has processed them, there is always some delay between a write on the leader and that write appearing on a follower. This delay is called replication lag.
Under normal conditions, replication lag is small (milliseconds to low seconds). Under heavy write load, network issues, or slow followers, it can grow to minutes or more.
This creates a practical problem. Say a client writes to the leader and then immediately reads from a follower. The follower may not have the write yet. The client sees stale data, even though the write already succeeded. This is the “read-your-writes” consistency problem that we covered in the CAP Theorem Series Part 4 consistency spectrum.

Where You’ll See It
PostgreSQL with streaming replication. One primary, one or more standbys.
MySQL with binary log replication. Same model: primary writes, replicas replay the binary log.
MongoDB replica sets. One primary, multiple secondaries. Elections happen automatically if the primary goes down.
Redis with replication. One master, one or more replicas, async by default.
Leader-follower is simple to reason about and simple to operate. There is exactly one source of truth for writes. The trade-off is that the leader is a bottleneck (all writes go through it) and a potential single point of failure (if the leader goes down, writes stop until a new leader is elected).
Multi-Leader Replication
Multi-leader (also called multi-master or active-active) replication allows more than one node to accept writes. Each leader processes writes independently and then replicates those writes to all other leaders.
So why would you want multiple leaders? The primary use case is multi-datacenter deployment. In a leader-follower setup with a single leader, all writes must travel to whichever datacenter holds the leader. If the leader is in us-east-1 and a user writes from Europe, that write has to cross the Atlantic. With multi-leader, you place a leader in each datacenter. European writes go to the European leader, American writes go to the American leader. Each leader replicates to the others asynchronously.

The Write Conflict Problem
The fundamental challenge of multi-leader replication is write conflicts. If two leaders accept a write to the same record at roughly the same time, their states diverge. When they replicate to each other, they discover a conflict: two different values for the same key, neither of which is “more correct” than the other.
 solve the problem cleanly. This is the central reason multi-leader replication is uncommon in practice.")
So how do you resolve this? There are several strategies, and none of them are perfect:
Last-write-wins (LWW) is the simplest approach. Attach a timestamp to each write, and the write with the highest timestamp wins. The problem is that this can silently discard data. If two writes happen at nearly the same time, one is thrown away without the user ever knowing.
Merge the values. Instead of picking a winner, combine the conflicting values. For example, if two users edit different fields of the same document, merge both edits. This works for some data types but breaks down for others (what does it mean to “merge” two conflicting updates to the same field?).
Push to the application. Store all conflicting versions and let the application (or the user) decide how to resolve them. This is what CouchDB does with its “revision tree.” It’s the most flexible strategy, but it pushes significant complexity onto the application developer.
Conflict resolution is genuinely hard, and it’s the primary reason multi-leader replication is far less common than leader-follower.
Where You’ll See It
CockroachDB in multi-region configurations. Each region has nodes that can accept writes, though CockroachDB uses consensus (Raft) within ranges in order to avoid the typical multi-leader conflict problem. This is worth noting because it blurs the line between multi-leader and something closer to distributed consensus.
MySQL Group Replication in multi-primary mode. Multiple nodes accept writes, with an internal certification process to detect and reject conflicting transactions.
Collaborative editing tools (Google Docs, Figma) are essentially multi-leader systems. Each user’s device is a “leader” that accepts local edits and replicates them to others. Conflict resolution is handled through Operational Transform (OT) or Conflict-free Replicated Data Types (CRDTs).
Leaderless Replication
Leaderless replication removes the concept of a leader entirely. Any node can accept both reads and writes. There is no single point that serializes writes and no replication stream flowing from one designated source.
So how does a leaderless system keep replicas in sync? The typical approach uses two mechanisms working together:
Write to multiple nodes simultaneously. When a client writes, it sends the write to multiple replicas (or all replicas) in parallel. The write is considered successful once a threshold of nodes acknowledge it.
Read from multiple nodes simultaneously. When a client reads, it queries multiple replicas and takes the most recent value (determined by a version number or timestamp).
That threshold is the quorum. For a system with N replicas, you choose a write quorum W and a read quorum R such that W + R > N. This guarantees that at least one node involved in any read will have the most recent write.
Why does this work? Consider a concrete example. With 3 replicas, set W = 2 and R = 2. Every write reaches at least 2 nodes. Every read checks at least 2 nodes. Since 2 + 2 > 3, there is always at least one node in the read set that participated in the most recent write. That overlap is what gives you the consistency guarantee.

Anti-Entropy and Read Repair
Quorums guarantee that reads can find the latest value, but they don’t guarantee that all replicas are up to date at all times. Two background mechanisms handle that:
Read repair works at query time. When a read detects that one replica returned a stale value, the client (or a coordinator node) writes the latest value back to the stale replica. The read itself triggers the fix.

Anti-entropy is a background process that periodically compares replicas and copies any missing data between them. This is often implemented using Merkle trees (check out my post about them a while back), which allow two nodes to efficiently identify exactly which pieces of data are out of sync without comparing every record.
Where You’ll See It
Apache Cassandra is the most well-known leaderless system. Writes go to multiple replicas determined by consistent hashing. The consistency level (ONE, QUORUM, ALL) is configurable per query, which means the application decides the trade-off between latency and consistency on every single operation.
Amazon DynamoDB uses a leaderless architecture internally. The original Dynamo paper describes quorum-based reads and writes with sloppy quorums and hinted handoff for handling temporarily unavailable nodes.
Riak (now largely succeeded by other systems) was another prominent leaderless key-value store built directly on the ideas from the Dynamo paper.
The Trade-Off
Leaderless systems have no single point of failure for writes. Any node can serve any request. This makes them highly available during network partitions (as we covered extensively in the CAP Theorem series when discussing AP systems).
The cost is consistency complexity. Without a leader to serialize writes, conflicts can occur. Stale reads are possible if quorum parameters are relaxed. And the application needs to understand that different consistency levels exist and choose appropriately for each operation. That operational burden is real, and it’s the price you pay for the availability guarantee.
Comparing the Three Models
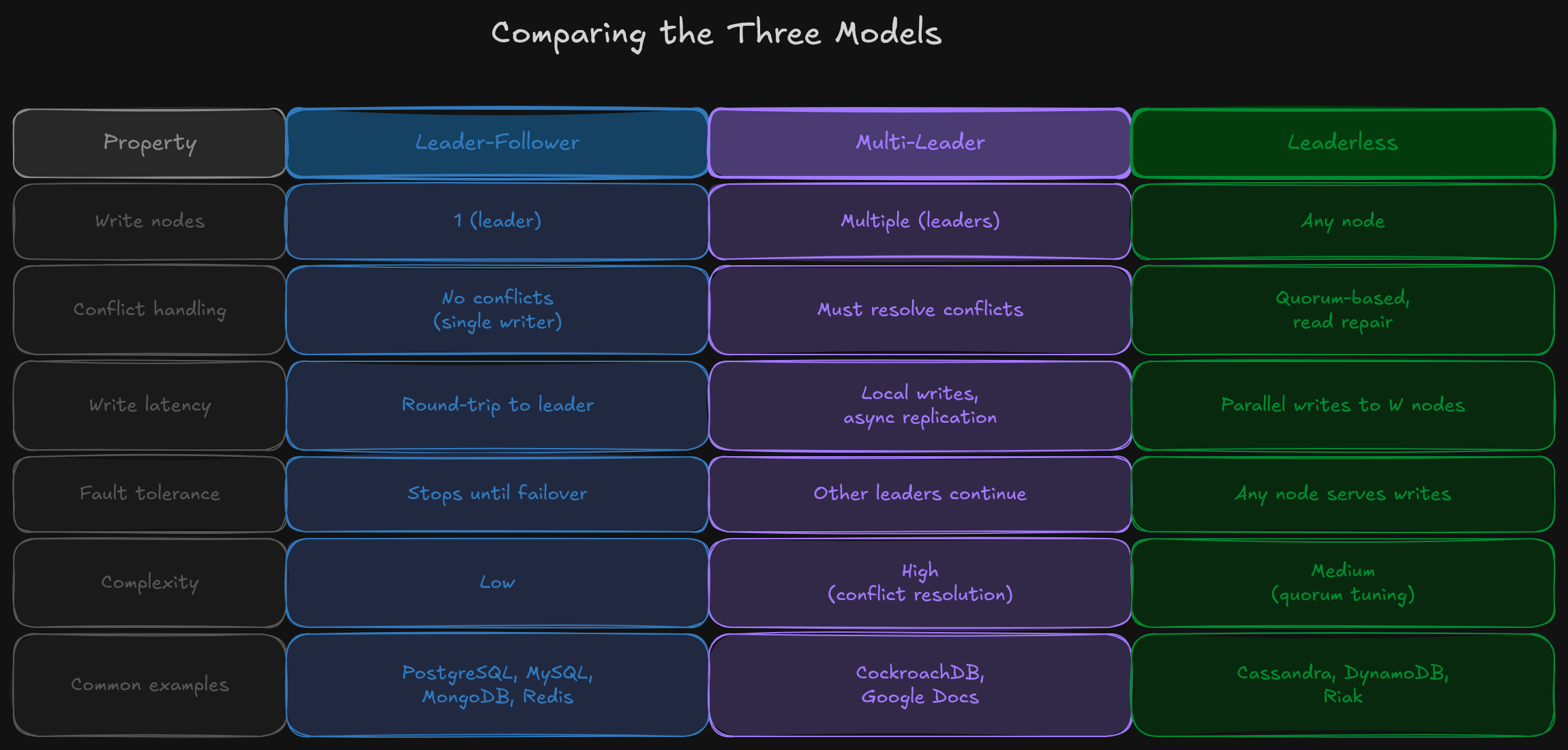
Limitations
Each replication model solves certain problems and introduces others:
Leader-follower is simple but creates a write bottleneck and requires failover mechanisms when the leader goes down. Multi-leader enables geographic write distribution but introduces write conflicts that are genuinely difficult to resolve correctly. Leaderless eliminates single points of failure but requires careful quorum tuning and doesn’t provide strong consistency by default.
It’s also worth noting what replication does not solve. None of these models address the problem of a dataset that’s too large to fit on a single node. Replication copies the same data to multiple nodes. In order to split different data across nodes, you need sharding, which is a separate concern entirely. Most production systems use both replication and sharding together.
All in All
Replication is a foundational building block in distributed systems. The three architectures (leader-follower, multi-leader, and leaderless) each make a different trade-off between simplicity, write availability, and consistency guarantees.
Leader-follower is the default for most applications. It’s simple, well-understood, and supported by nearly every database. Multi-leader is primarily used for multi-datacenter deployments where cross-region write latency is unacceptable. Leaderless is the choice when high write availability is the priority and the application can tolerate the complexity of quorum-based consistency.
Understanding these models is essential in order to make informed decisions about database architecture. The choice of replication model directly affects how your system behaves during failures, which is exactly the question the CAP Theorem asks.
— Ali
References
Designing Data-Intensive Applications, Martin Kleppmann, Chapter 5 (Replication)
Dynamo: Amazon’s Highly Available Key-value Store, DeCandia et al. (2007)